
Mogo et l'algorithme UCT pour le jeu de Go
Mogo et l'algorithme UCT battent un adversaire humain de niveau Maître au jeu de Go pour la première fois le 22 mars 2008 dans un tournoi organisé par la Fédération Française de Go.
Le jeu de Go
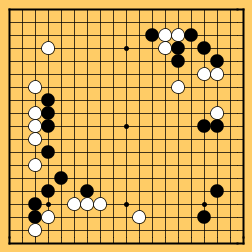 C'est un jeu d'origine chinois
qui se joue sur un tablier nommé goban de 19 x 19 cases mais que l'on
réduit souvent à 13 x 13 ou 9 x 9 cases.
C'est un jeu d'origine chinois
qui se joue sur un tablier nommé goban de 19 x 19 cases mais que l'on
réduit souvent à 13 x 13 ou 9 x 9 cases.
Les joueurs y disposent de pierres blanches ou noires qu'ils posent aux
intersections des lignes du tablier, à tour de rôle, le but
étant d'encercler les pierres de l'adversaire pour marquer des points.
Dans ce duel historique contre l'ordinateur, c'était un plateau réduit
de 9 x 9 cases qui était utilisé.
Le jeu de Go ressemble a l'Othello qui se joue sur un plateau de 8 x 8 cases. Dans Othello les pions encerclés prennent la couleur des pions qui l'encerclent et donc changent de possesseur. Le Reversi est une variante de l'Othello.
Les logiciels Othello-Reversi avec l'ordinateur comme adversaire existent depuis longtemps et pour remplacer le joueur humain utilisent des algorithmes simples comme l'alpha-beta.
Le Go n'a rien à voir avec le Gomoku qui est dérivé du jeu du Morpion. Celui-ci à 3x3 cases et le but est de créer une ligne ou diagonale de trois pions de même couleur.
Mogo et l'algorithme UCT
En 1998, le programme Deeper Blue sur IBM a battu pour la première fois un maître d'échecs, Gary Kasparov. Cependant le jeu de Go est plus difficile à programmer car le nombre de coups à prédire est virtuellement illimité.
Le meilleur programme de joueur de Go actuellement est Mogo, développé
par l'INRIA, le CNRS et Paris-Sud.
Ce programme utilise l'algorithme UCT pour parcourir l'arborescence des
coups possibles.
UCT, Upper bound Confidence for Tree. (Trad.: Limite supérieure de confiance en arborescence) est dérivé de UCB, Upper Confidence Bounds. (Trad.: Limites supérieures de confiance) et inclut l'emploi de Monte-Carlo pour fonction d'évaluation.
L'arborescence est parcourue à partir de la racine, la position actuelle du pion et il est parcouru selon l'algorithme UTC jusqu'à ce qu'on parvienne à un noeud terminal. A ce moment une fonction d'évaluation est appliquée nommé Monte-Carlo. L'UCT parcourt plusieurs fois les mêmes branches, mais elles sont évaluées chaque fois et donc il tendra à parcourir les branches les plus prometteuses.
La version amliorée de l'algo UCT utilise la simulation de Monte-Carlo qui consiste à remplir
le jeu de pions de façon non calculée et à compter
les points de chaque joueur pour donner une valeur à ce noeud terminal.
Ce nom Monte-Carlo fait référence aux casinos de la principauté et donc au jeu de hasard, qui est à
la base de la méthode employée.
Références: Mogo, maître du jeu? L'explication de l'algorithme, et UCT et Monte Carlo, présentation du programme Mogo. (PDF)